Page: 1
/ 14
Total 110 questions
Splunk SPLK-2003 Splunk SOAR Certified Automation Developer Exam Practice Test
Question 1
Two action blocks, geolocate_ip 1 and file_reputation_2, are connected to a decision block. Which of the following is a correct configuration for making a decision on the action results from one of the given blocks?
A.

B.

C.
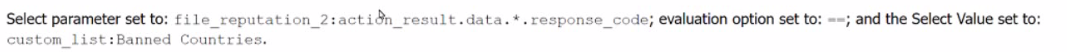
D.

Answer : A
In the given decision block, you are trying to evaluate the results of two action blocks: geolocate_ip_1 and file_reputation_2. The correct configuration for making a decision based on the result of geolocate_ip_1 is by checking the country_iso_code field from the action result and setting the evaluation option to != (not equal), with no specific value provided in the 'Select Value' box. This essentially checks whether a valid country ISO code exists in the action result and proceeds if it's not empty or different from a specific value. This is a common check when working with geolocation results to see if a response has been returned.
Other options (B, C, and D) include response codes or list comparisons, which do not align with the decision structure mentioned, which needs to operate based on a country_iso_code field.
Splunk SOAR Playbook Development Guide.
Splunk SOAR Documentation on Decision Blocks and Action Result Evaluation.
Question 2
Which visual playbook editor block is used to assemble commands and data into a valid Splunk search within a SOAR playbook?
Answer : C
In Splunk SOAR playbook development, the format block is used to assemble commands and data into a valid Splunk search query. This block allows users to structure and manipulate strings, dynamically inserting variables, and constructing the precise format needed for a search query. By using a format block, playbooks can integrate data from various sources and ensure that it is assembled correctly before passing it to subsequent actions, such as executing a Splunk search.
Other blocks, like action, filter, and prompt blocks, serve different purposes (e.g., running actions, filtering data, or prompting for user input), but the format block is specifically designed for building structured data or queries like Splunk searches.
Splunk SOAR Documentation: Playbook Blocks Overview.
Splunk SOAR Playbook Editor Guide: Using the Format Block.
Question 3
Which of the following are tabs of an asset configuration?
Answer : D
In Splunk SOAR, the asset configuration consists of several key tabs that are essential for setting up and managing an asset. These tabs include:
Asset Info: Contains general information about the asset, such as its name and description.
Asset Settings: This tab allows for configuring specific settings related to the asset, including any connections or integrations.
Approval Settings: This section manages settings related to the approval process for actions that require explicit authorization.
Access Control: This tab helps control user access to the asset, specifying permissions and roles.
These four tabs are essential for configuring an asset in SOAR, making sure the asset works as expected and that the right people have access to it.
Splunk SOAR Documentation: Asset Configuration.
Splunk SOAR Best Practices: Asset Management and Configuration.
Question 4
Which of the following is the best option for an analyst who wants to run a single action on an event?
Answer : A
The best option for an analyst who wants to run a single action on an event is to open the event and run the action directly from the Investigation View. The Investigation View allows users to interact with events directly, and provides the ability to execute specific actions without the need for playbook development or debugging. This is the most straightforward and efficient way to execute a single action on an event, without the overhead of creating or editing playbooks.
While creating a playbook and using the Playbook Debugger are viable options, they introduce unnecessary complexity for running just one action. The goal is to allow the analyst to act quickly and efficiently within the Investigation View.
Splunk SOAR Documentation: Investigation View Overview.
Splunk SOAR Best Practices for Running Actions on Events.
Question 5
How can parent and child playbooks pass information to each other?
Answer : A
In Splunk SOAR, parent and child playbooks can pass information between each other using arguments. The parent playbook can pass specific arguments to the child playbook when it is called, enabling the child playbook to utilize these values in its execution. Once the child playbook finishes its execution, it can return values through the end block. This mechanism allows for efficient and structured communication between parent and child playbooks, enabling complex, multi-step automation workflows.
Other options are incorrect because creating artifacts with specific naming conventions is not necessary for passing information between playbooks, and artifacts are not used for argument or result passing between playbooks in this manner.
Splunk SOAR Documentation: Playbook Development Guide.
Splunk SOAR Best Practices: Parent and Child Playbooks Communication.
Question 6
Which of the following cannot be marked as evidence in a container?
Answer : D
In Splunk SOAR, the following elements can be marked as evidence within a container: action results, artifacts, and notes. These are crucial elements that contribute directly to incident analysis and can be selected as evidence to support investigation outcomes or legal proceedings.
However, comments cannot be marked as evidence. Comments are usually informal and meant for communication between users, providing context or updates but not serving as formal evidence within the system. Action results, artifacts, and notes, on the other hand, contain critical data related to the incident that could be useful for audit and investigative purposes, making them eligible to be marked as evidence.
Splunk SOAR Documentation: Working with Evidence.
Splunk SOAR Best Practices: Evidence Collection and Management.
Question 7
Which of the following views provides a holistic view of an incident - providing event metadata, Service Level Agreement status, Severity, sensitivity of an event, and other detailed event info?
Answer : B
The Investigation view in Splunk SOAR provides a comprehensive and holistic view of an incident. This view includes vital details such as event metadata, Service Level Agreement (SLA) status, severity, sensitivity of the event, and other relevant information. It allows analysts to track and manage incidents effectively by presenting a clear picture of all aspects of the investigation process. This view is designed to help users take timely actions based on critical data points, making it a pivotal feature for incident response teams.
Other views like Executive or Analyst may focus on specific reporting or technical details, but the Investigation view provides the most complete perspective on the incident and its progress.
Splunk SOAR Documentation: Investigation View Overview.
Splunk SOAR Incident Response Best Practices.