Page: 1
/ 14
Total 78 questions
Snowflake ADA-C01 SnowPro Advanced: Administrator Certification Exam Practice Test
Question 1
Which function is the role SECURITYADMIN responsible for that is not granted to role USERADMIN?
Answer : B
According to the Snowflake documentation1, the SECURITYADMIN role is responsible for managing all grants on objects in the account, including system grants. The USERADMIN role can only create and manage users and roles, but not grant privileges on other objects. Therefore, the function that is unique to the SECURITYADMIN role is to manage system grants. Option A is incorrect because both roles can reset a user's password. Option C is incorrect because both roles can create new users. Option D is incorrect because both roles can create new roles.
Question 2
A team is provisioning new lower environments from the production database using cloning. All production objects and references reside in the database, and do not have
external references.
What set of object references needs to be re-pointed before granting access for usage?
Answer : C
According to the Snowflake documentation1, when an object in a schema is cloned, any future grants defined for this object type in the schema are applied to the cloned object unless the COPY GRANTS option is specified in the CREATE statement for the clone operation. However, some objects may still reference the source object or external objects after cloning, which may cause issues with access or functionality. These objects include:
* Sequences: If a table column references a sequence that generates default values, the cloned table may reference the source or cloned sequence, depending on where the sequence is defined. To avoid conflicts, the sequence reference should be re-pointed to the desired sequence using the ALTER TABLE command2.
* Storage integrations: If a stage or a table references a storage integration, the cloned object may still reference the source storage integration, which may not be accessible or valid in the new environment. To avoid errors, the storage integration reference should be re-pointed to the desired storage integration using the ALTER STAGE or ALTER TABLE command34.
* Views, secure views, and materialized views: If a view references another view or table, the cloned view may still reference the source object, which may not be accessible or valid in the new environment. To avoid errors, the view reference should be re-pointed to the desired object using the CREATE OR REPLACE VIEW command5.
1: Cloning Considerations | Snowflake Documentation 2: [ALTER TABLE | Snowflake Documentation] 3: [ALTER STAGE | Snowflake Documentation] 4: [ALTER TABLE | Snowflake Documentation] 5: [CREATE VIEW | Snowflake Documentation]
Question 3
What are the requirements when creating a new account within an organization in Snowflake? (Select TWO).
Answer : C, E
According to the CREATE ACCOUNT documentation, the account name must be specified when the account is created, and it must be unique within an organization, regardless of which Snowflake Region the account is in. The other options are incorrect because:
* The account does not require at least one ORGADMIN role within one of the organization's accounts. The account can be created by an organization administrator (i.e. a user with the ORGADMIN role) through the web interface or using SQL, but the new account does not inherit the ORGADMIN role from the existing account. The new account will have its own set of users, roles, databases, and warehouses.
* The account name is not immutable and can be changed. The account name can be modified by contacting Snowflake Support and requesting a name change. However, changing the account name may affect some features that depend on the account name, such as SSO or SCIM.
* The account name does not need to be unique among all Snowflake customers. The account name only needs to be unique within the organization, as the account URL also includes the region and cloud platform information. For example, two accounts with the same name can exist in different regions or cloud platforms, such as myaccount.us-east-1.snowflakecomputing.com and myaccount.eu-west-1.aws.snowflakecomputing.com.
Question 4
A resource monitor named MONTHLY_FINANCE_LIMIT has been created and applied to two virtual warehouses (fin_wh1 and fin_wh2) using the following SQL:
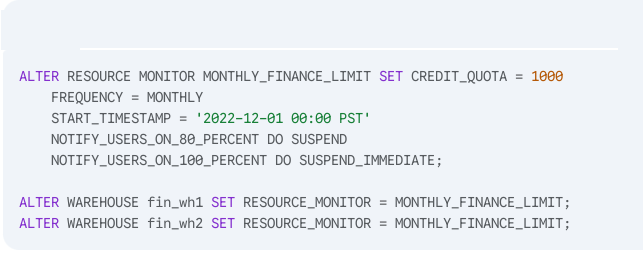
Given that the combined total of credits consumed by fin_wh1 and fin_wh2 (including cloud services) has reached 800 credits and both warehouses are suspended, what should the ACCOUNTADMIN execute to allow both warehouses to be resumed? (Select TWO).
Answer : E, F
Scenario:
Resource Monitor MONTHLY_FINANCE_LIMIT has a credit quota of 1000.
800 credits have been used and warehouses are already suspended.
According to monitor configuration:
At 80%, warehouses are suspended.
At 100%, warehouses would be suspended immediately.
Warehouses cannot resume until the monitor is reset or the quota is increased.
E. SET CREDIT_QUOTA = 1500
Increases the monthly credit limit to 1500.
Since current usage is 800 < 1500, this puts usage below 80%.
This allows resumption of warehouses.
F. RESET
sql
CopyEdit
ALTER RESOURCE MONITOR MONTHLY_FINANCE_LIMIT RESET;
Resets usage to zero for the current period.
Allows warehouses to resume immediately --- same effect as a fresh cycle.
Why Other Options Are Incorrect:
A . / B. ALTER WAREHOUSE ... RESUME
Won't work while the resource monitor is actively suspending the warehouses due to limits.
C . / D. UNSET RESOURCE_MONITOR
You can't remove a resource monitor from a warehouse while it is currently suspended by that same monitor.
You must first reset or adjust the monitor.
G . UNSET RESOURCE_MONITORS
Invalid syntax --- there's no RESOURCE_MONITORS plural keyword.
SnowPro Administrator Reference:
Resource Monitors Overview
ALTER RESOURCE MONITOR
Best Practices for Controlling Warehouse Credit Usage
Question 5
A Snowflake Administrator needs to retrieve the list of the schemas deleted within the last two days from the DB1 database.
Which of the following will achieve this?
Answer : B
To retrieve a list of schemas deleted within the last 2 days from the DB1 database, you need a metadata view that includes historical data, including dropped (deleted) objects.
Let's review the options:
B. SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA
This is the correct choice because:
It includes metadata for all schemas, even deleted ones, within the retention period.
It contains a DELETED column and a DELETED_ON timestamp column.
You can filter rows with:
sql
CopyEdit
SELECT *
FROM SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA
WHERE DELETED IS TRUE
AND DELETED_ON >= DATEADD(DAY, -2, CURRENT_TIMESTAMP())
AND CATALOG_NAME = 'DB1';
A. SHOW SCHEMAS IN DATABASE DB1;
Only shows current (active) schemas --- does not include deleted schemas.
C. DB1.INFORMATION_SCHEMA.SCHEMATA
Like option A, this view only includes active schemas in the current database.
No info on deleted schemas is retained.
D. SNOWFLAKE.ACCOUNT_USAGE.DATABASES
This metadata view tracks databases, not individual schemas.
SnowPro Administrator Reference:
SNOWFLAKE.ACCOUNT_USAGE.SCHEMATA documentation
Metadata includes both active and deleted schemas (within retention window).
Question 6
What are the MINIMUM grants required on the database, schema, and table for a stream to be properly created and managed?
Answer : A
Question 7
Which actions are considered breaking changes to data that is shared with consumers in the Snowflake Marketplace? (Select TWO).
Answer : A, D
According to the Snowflake documentation1, breaking changes are changes that affect the schema or structure of the shared data, such as dropping or renaming a column or a table. These changes may cause errors or unexpected results for the consumers who query the shared data. Deleting data from a table, unpublishing the data listing, or adding region availability to the listing are not breaking changes, as they do not alter the schema or structure of the shared data.
1: Managing Data Listings in Snowflake Data Marketplace | Snowflake Documentation