Page: 1
/ 14
Total 152 questions
Salesforce Certified MuleSoft Platform Architect (Mule-Arch-201) Exam Practice Test
Question 1
A new upstream API Is being designed to offer an SLA of 500 ms median and 800 ms maximum (99th percentile) response time. The corresponding API implementation needs to sequentially invoke 3 downstream APIs of very similar complexity.
The first of these downstream APIs offers the following SLA for its response time: median: 100 ms, 80th percentile: 500 ms, 95th percentile: 1000 ms.
If possible, how can a timeout be set in the upstream API for the invocation of the first downstream API to meet the new upstream API's desired SLA?
Answer : B
Correct Answe r: Set a timeout of 100ms; that leaves 400ms for other two downstream APIs to complete
*****************************************
Key details to take from the given scenario:
>> Upstream API's designed SLA is 500ms (median). Lets ignore maximum SLA response times.
>> This API calls 3 downstream APIs sequentially and all these are of similar complexity.
>> The first downstream API is offering median SLA of 100ms, 80th percentile: 500ms; 95th percentile: 1000ms.
Based on the above details:
>> We can rule out the option which is suggesting to set 50ms timeout. Because, if the median SLA itself being offered is 100ms then most of the calls are going to timeout and time gets wasted in retried them and eventually gets exhausted with all retries. Even if some retries gets successful, the remaining time wont leave enough room for 2nd and 3rd downstream APIs to respond within time.
>> The option suggesting to NOT set a timeout as the invocation of this API is mandatory and so we must wait until it responds is silly. As not setting time out would go against the good implementation pattern and moreover if the first API is not responding within its offered median SLA 100ms then most probably it would either respond in 500ms (80th percentile) or 1000ms (95th percentile). In BOTH cases, getting a successful response from 1st downstream API does NO GOOD because already by this time the Upstream API SLA of 500 ms is breached. There is no time left to call 2nd and 3rd downstream APIs.
>> It is NOT true that no timeout is possible to meet the upstream APIs desired SLA.
As 1st downstream API is offering its median SLA of 100ms, it means MOST of the time we would get the responses within that time. So, setting a timeout of 100ms would be ideal for MOST calls as it leaves enough room of 400ms for remaining 2 downstream API calls.
Question 2
When should idempotency be taken into account?
Answer : D
Understanding Idempotency:
Idempotency is a concept in APIs where an operation can be performed multiple times without changing the result beyond the initial application. This is particularly important for operations that may be repeated due to network retries or client errors.
When to Consider Idempotency:
Idempotency should be taken into account when there is a risk of duplicate processing due to multiple requests being sent (e.g., retries or errors). This ensures that repeated requests do not result in unintended side effects, such as creating multiple records or processing the same transaction more than once.
Evaluating the Options:
Option A: While locked entities may need special handling, this is not directly related to idempotency.
Option B: Storing results for future responses could be useful but does not relate to idempotent operations.
Option C: Concurrent requests for the same entity might require handling for conflicts, but this scenario is better suited for transaction management or concurrency control.
Option D (Correct Answer): Preventing duplicate processing from multiple requests is a key reason to implement idempotency, ensuring that repeat requests have no adverse effects.
Conclusion:
Option D is the correct answer as idempotency is specifically used to handle scenarios where duplicate requests might be sent, preventing unintended processing.
Refer to MuleSoft's documentation on best practices for idempotency in API design for more details.
Question 3
An existing Quoting API is defined in RAML and used by REST clients for interacting with the quoting engine. Currently there is a resource defined in the RAML that allows the creation of quotes; however, a new requirement was just received to allow for the updating of existing quotes.
Which two actions need to be taken to facilitate this change so it can be processed?
Choose 2 answers
Answer : A, C
To accommodate the new requirement of allowing updates to existing quotes, the following actions should be taken:
Update the RAML Definition (Option C):
The RAML specification defines the structure and behavior of the API. Adding a new method (such as PUT or PATCH) for updating quotes requires modifying the RAML to include this new endpoint. This ensures the API specification is up-to-date and accurately reflects the new functionality.
Update the API Implementation (Option A):
Once the RAML is updated, the backend API implementation must also be modified to handle the new update requests. This could involve adding logic to process and validate update requests, connect to necessary backend resources, and apply the changes to existing quotes.
of Incorrect Options:
Option B (removing and creating new clients) is unnecessary; client applications can remain as they are, with no need for complete replacement.
Option D (deprecating existing versions) may not be required if backward compatibility is maintained.
Option E (adding a new policy) does not facilitate functional changes and is unrelated to implementing the update feature.
Reference For more details on updating RAML definitions and API implementations, refer to MuleSoft's API Design documentation on RAML and RESTful API practices.
Question 4
An Order API must be designed that contains significant amounts of integration logic and involves the invocation of the Product API.
The power relationship between Order API and Product API is one of "Customer/Supplier", because the Product API is used heavily throughout the organization and is developed by a dedicated development team located in the office of the CTO.
What strategy should be used to deal with the API data model of the Product API within the Order API?
Answer : C
Correct Answe r: Convince the development team of the product API to adopt the API data model of the Order API such that integration logic of the Order API can work with one consistent internal data model
*****************************************
Key details to note from the given scenario:
>> Power relationship between Order API and Product API is customer/supplier
So, as per below rules of 'Power Relationships', the caller (in this case Order API) would request for features to the called (Product API team) and the Product API team would need to accomodate those requests.
Question 5
Several times a week, an API implementation shows several thousand requests per minute in an Anypoint Monitoring dashboard, Between these bursts, the
dashboard shows between two and five requests per minute. The API implementation is running on Anypoint Runtime Fabric with two non-clustered replicas, reserved vCPU 1.0
and vCPU Limit 2.0.
An API consumer has complained about slow response time, and the dashboard shows the 99 percentile is greater than 120 seconds at the time of the complaint. It also shows
greater than 90% CPU usage during these time periods.
In manual tests in the QA environment, the API consumer has consistently reproduced the slow response time and high CPU usage, and there were no other API requests at
this time. In a brainstorming session, the engineering team has created several proposals to reduce the response time for requests.
Which proposal should be pursued first?
Answer : A
Scenario Analysis:
The API implementation is experiencing high CPU usage (over 90%) during bursts of requests, which correlates with slow response times, as indicated by a 99th percentile response time greater than 120 seconds.
The API implementation is running on Anypoint Runtime Fabric with two non-clustered replicas and has a reserved vCPU of 1.0 and a vCPU limit of 2.0.
The high CPU usage during bursts suggests that the current resources may not be sufficient to handle peak loads.
Evaluating the Options:
Option A (Correct Answer): Increasing the vCPU resources for each replica would provide more processing power to handle high traffic volumes, potentially reducing the response time during spikes. Since the CPU usage is consistently high during bursts, this option directly addresses the resource bottleneck.
Option B: Modifying the API client to split requests may reduce individual request load but could be complex to implement on the client side and may not fully address the high CPU issue.
Option C: Increasing the number of replicas could help distribute the load; however, with a high CPU load on each replica, adding more replicas without increasing CPU resources may not fully resolve the problem.
Option D: Throttling the client would reduce the number of requests, but this may not be acceptable if the client needs to maintain a high request rate. It also does not directly address the CPU limitations of the API implementation.
Conclusion:
Option A is the best choice as it addresses the root cause of high CPU usage by increasing the vCPU allocation, allowing the API to handle more requests efficiently. This should be pursued first before considering other options.
Refer to MuleSoft's documentation on Runtime Fabric and vCPU resource allocation for more details on optimizing API performance in high-demand environments.
Question 6
Refer to the exhibit.
What is a valid API in the sense of API-led connectivity and application networks?
A) Java RMI over TCP
B) Java RMI over TCP
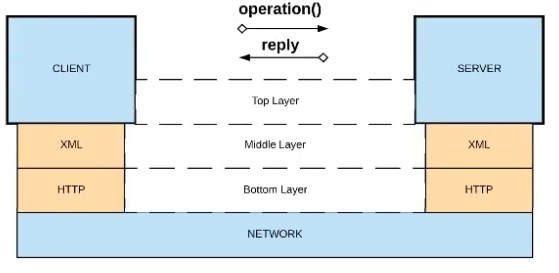
C) CORBA over HOP
D) XML over UDP
Answer : D
Correct Answe r:XML over HTTP
*****************************************
>>API-led connectivity and Application Networks urge to have the APIs on HTTP based protocols for building most effective APIs and networks on top of them.
>>The HTTP based APIs allow the platform to apply various varities of policies to address many NFRs
>>The HTTP based APIs also allow to implement many standard and effective implementation patterns that adhere to HTTP based w3c rules.
Bottom of Form
Top of Form
Question 7
Which statement is true about Spike Control policy and Rate Limiting policy?
Answer : B
Understanding Spike Control and Rate Limiting Policies:
Spike Control Policy: Limits the number of requests processed by the API in a short time to handle sudden bursts of traffic. It does not queue requests but rejects any request that exceeds the allowed burst rate.
Rate Limiting Policy: Sets a limit on the number of requests that an API can handle within a given timeframe. Once the limit is reached, additional requests are rejected.
Evaluating the Options:
Option A: Incorrect. In both Spike Control and Rate Limiting policies, requests are rejected once the limit is reached. Spike Control does not queue requests; it only controls the burst rate by rejecting excessive requests.
Option B (Correct Answer): In a clustered environment, each node independently enforces the Rate Limiting and Spike Control policies, meaning that the limits apply to each node separately. This ensures that each node can control its own resource usage independently within the cluster.
Option C: This is partially correct, as Rate Limiting is often used to protect Experience APIs, but Spike Control could also be useful in limiting resource consumption under high burst conditions.
Option D: Incorrect. Although a contract is required to enforce client-specific policies, Rate Limiting and Spike Control do not require a contract to function for general traffic control.
Conclusion:
Option B is the correct answer because, in a clustered environment, Rate Limiting and Spike Control policies apply separately to each node, helping each instance to manage its own load.
For more information, refer to MuleSoft's documentation on applying Rate Limiting and Spike Control policies in a clustered environment.