Page: 1
/ 14
Total 306 questions
Microsoft DP-900 Microsoft Azure Data Fundamentals Exam Practice Test
Question 1
You need to recommend a non-relational data store that is optimized for storing and retrieving files, videos, audio stream, and virtual disk images. The data store must store data, some metadata, and a unique ID for each file.
Which type of data store should you rec ommend?
Answer : C
Object storage is optimized for storing and retrieving large binary objects (images, files, video and audio streams, large application data objects and documents, virtual machine disk images). Large data files are also popularly used in this model, for example, delimiter file (CSV), parquet, and ORC. Object stores can manage extremely large amounts of unstructured data.
https://docs.microsoft.com/en-us/azure/architecture/guide/technology-choices/data-store-overview
Question 2
Which Azure storage solution provides native support for POSIX-compliant access control lists (ACLs)?
Question 3
Your company is designing a data store that will contain student dat
a. The data has the following format.
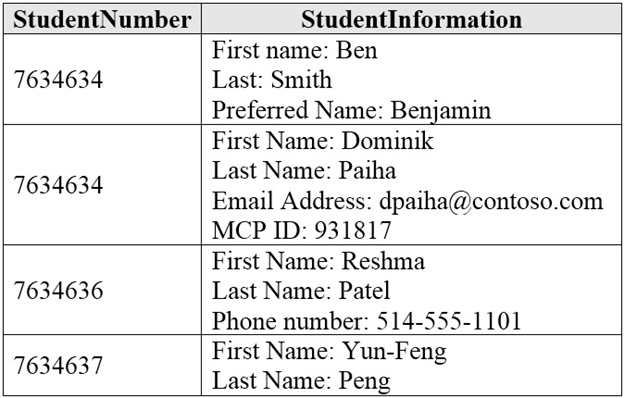
Which type of data store should you use?
Answer : D
Question 4
You need to store data in Azure Blob storage for seven years to meet your company's compliance
requirements. The retrieval time of the data is unimportant. The solution must minimize storage costs.
Which storage tier should you use?
Answer : A
Question 5
You need to query a table named Products in an Azure SQL database.
Which three requirements must be met to query the table from the internet? Each correct answer presents part of the solution. (Choose three.)
NOTE: Each correct selection is worth one point.
Question 6
You need to create an Azure resource to store data in Azure Table storage.
Which command should you run?
Question 7
Which service is optimized for loT scenarios that involve streaming time series data?
Answer : D