Page: 1
/ 14
Total 354 questions
Microsoft DP-203 Data Engineering on Microsoft Azure Exam Practice Test
Question 1
You have an Azure subscription that contains an Azure SQL database named SQLDB1 and an Azure Synapse Analytics dedicated SQL pool named Pool1.
You need to replicate data from SQLDB1 to Pool1. The solution must meet the following requirements:
* Minimize performance impact on SQLDB1.
* Support near-real-time (NRT) analytics.
* Minimize administrative effort.
What should you use?
Answer : A
Question 2
You have an Azure Stream Analytics job named Job1.
The metrics of Job1 from the last hour are shown in the following table.
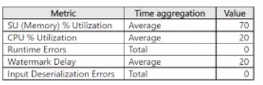
The late arrival tolerance for Job1 is set to the five seconds.
You need to optimize Job1.
Which two actions achieve the goal? Each correct answer presents a complete solution.
NOTE: Each correct answer is worth one point.
Answer : B, D
Question 3
You have an Azure Stream Analytics job that read data from an Azure event hub.
You need to evaluate whether the job processes data as quickly as the data arrives or cannot keep up.
Which metric should you review?
Answer : B
Question 4
You have an Azure Synapse Analytics workspace.
You plan to deploy a lake database by using a database template in Azure Synapse.
Which two elements ate included in the template? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point
Answer : A, B
Question 5
You have an Azure subscription that contains an Azure Data Factory data pipeline named Pipeline1, a Log Analytics workspace named LA1, and a storage account named account1.
You need to retain pipeline-run data for 90 days. The solution must meet the following requirements:
* The pipeline-run data must be removed automatically after 90 days.
* Ongoing costs must be minimized.
Which two actions should you perform? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Answer : A, B
Question 6
You have an Azure data factory that connects to a Microsoft Purview account. The data factory is registered in Microsoft Purview.
You update a Data Factory pipeline.
You need to ensure that the updated lineage is available in Microsoft Purview.
What You have an Azure subscription that contains an Azure SQL database named DB1 and a storage account named storage1. The storage1 account contains a file named File1.txt. File1.txt contains the names of selected tables in DB1.
You need to use an Azure Synapse pipeline to copy data from the selected tables in DB1 to the files in storage1. The solution must meet the following requirements:
* The Copy activity in the pipeline must be parameterized to use the data in File1.txt to identify the source and destination of the copy.
* Copy activities must occur in parallel as often as possible.
Which two pipeline activities should you include in the pipeline? Each correct answer presents part of the solution. NOTE: Each correct selection is worth one point.
Answer : A, D
Question 7
You have a Microsoft Purview account. The Lineage view of a CSV file is shown in the following exhibit.
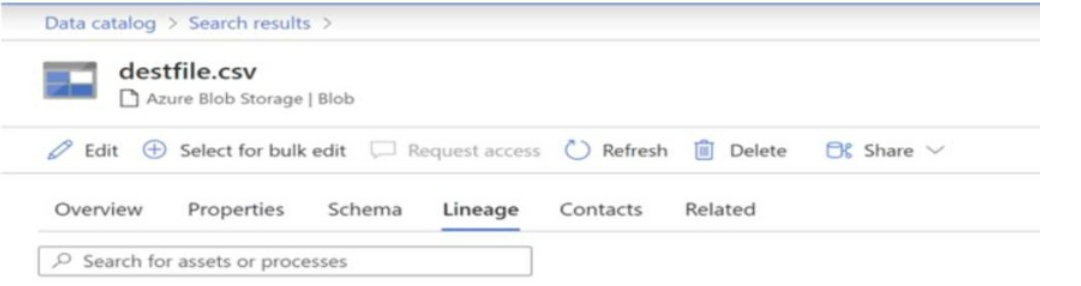
How is the data for the lineage populated?