Page: 1
/ 14
Total 461 questions
Microsoft DP-100 Designing and Implementing a Data Science Solution on Azure Exam Practice Test
Question 1
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are analyzing a numerical dataset which contain missing values in several columns.
You must clean the missing values using an appropriate operation without affecting the dimensionality of the feature set.
You need to analyze a full dataset to include all values.
Solution: Use the last Observation Carried Forward (IOCF) method to impute the missing data points.
Does the solution meet the goal?
Answer : B
Instead use the Multiple Imputation by Chained Equations (MICE) method.
Replace using MICE: For each missing value, this option assigns a new value, which is calculated by using a method described in the statistical literature as 'Multivariate Imputation using Chained Equations' or 'Multiple Imputation by Chained Equations'. With a multiple imputation method, each variable with missing data is modeled conditionally using the other variables in the data before filling in the missing values.
Note: Last observation carried forward (LOCF) is a method of imputing missing data in longitudinal studies. If a person drops out of a study before it ends, then his or her last observed score on the dependent variable is used for all subsequent (i.e., missing) observation points. LOCF is used to maintain the sample size and to reduce the bias caused by the attrition of participants in a study.
https://methods.sagepub.com/reference/encyc-of-research-design/n211.xml
Question 2
You use Azure Machine Learning Studio to build a machine learning experiment.
You need to divide data into two distinct datasets.
Which module should you use?
Answer : A
Partition and Sample with the Stratified split option outputs multiple datasets, partitioned using the rules you specified.
https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/partition-and-sample
Question 3
You manage an Azure Machine Learning workspace.
You must log multiple metrics by using MLflow.
You need to maximize logging performance.
What are two possible ways to achieve this goal? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Answer : A, B
Question 4
You retrain an existing model.
You need to register the new version of a model while keeping the current version of the model in the registry.
What should you do?
Answer : B
Model version: A version of a registered model. When a new model is added to the Model Registry, it is added as Version 1. Each model registered to the same model name increments the version number.
https://docs.microsoft.com/en-us/azure/databricks/applications/mlflow/model-registry
Question 5
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
An IT department creates the following Azure resource groups and resources:
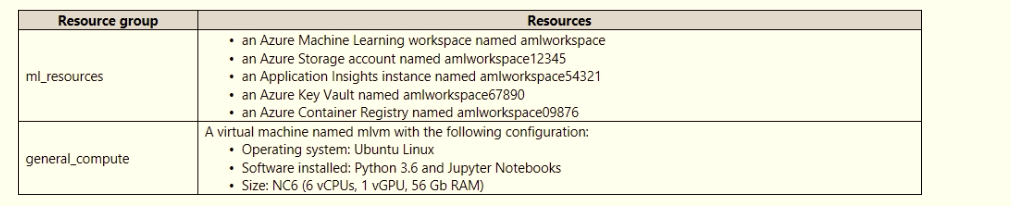
The IT department creates an Azure Kubernetes Service (AKS)-based inference compute target named aks-cluster in the Azure Machine Learning workspace.
You have a Microsoft Surface Book computer with a GPU. Python 3.6 and Visual Studio Code are installed.
You need to run a script that trains a deep neural network (DNN) model and logs the loss and accuracy metrics.
Solution: Install the Azure ML SDK on the Surface Book. Run Python code to connect to the workspace and then run the training script as an experiment on local compute.
Answer : B
Need to attach the mlvm virtual machine as a compute target in the Azure Machine Learning workspace.
https://docs.microsoft.com/en-us/azure/machine-learning/concept-compute-target
Question 6
You plan to deliver a hands-on workshop to several students. The workshop will focus on creating data
visualizations using Python. Each student will use a device that has internet access.
Student devices are not configured for Python development. Students do not have administrator access to
install software on their devices. Azure subscriptions are not available for students.
You need to ensure that students can run Python-based data visualization code.
Which Azure tool should you use?
Question 7
You have a Python script that executes a pipeline. The script includes the following code:
from azureml.core import Experiment
pipeline_run = Experiment(ws, 'pipeline_test').submit(pipeline)
You want to test the pipeline before deploying the script.
You need to display the pipeline run details written to the STDOUT output when the pipeline completes.
Which code segment should you add to the test script?
Answer : B
wait_for_completion: Wait for the completion of this run. Returns the status object after the wait.
Syntax: wait_for_completion(show_output=False, wait_post_processing=False, raise_on_error=True)
Parameter: show_output
Indicates whether to show the run output on sys.stdout.