Page: 1
/ 14
Total 59 questions
Databricks-Certified-Data-Analyst-Associate Databricks Certified Data Analyst Associate Exam Practice Test
Question 1
A data analyst wants to create a Databricks SQL dashboard with multiple data visualizations and multiple counters. What must be completed before adding the data visualizations and counters to the dashboard?
Answer : A
Question 2
Which location can be used to determine the owner of a managed table?
Answer : A
Question 3
A data scientist has asked a data analyst to create histograms for every continuous variable in a data set. The data analyst needs to identify which columns are continuous in the data set.
What describes a continuous variable?
Answer : C
Question 4
A data analyst needs to share a Databricks SQL dashboard with stakeholders that are not permitted to have accounts in the Databricks deployment. The stakeholders need to be notified every time the dashboard is refreshed.
Which approach can the data analyst use to accomplish this task with minimal effort/
Answer : B
Question 5
Where in the Databricks SQL workspace can a data analyst configure a refresh schedule for a query when the query is not attached to a dashboard or alert?
Answer : C
Question 6
What is a benefit of using Databricks SQL for business intelligence (Bl) analytics projects instead of using third-party Bl tools?
Answer : A
Question 7
A data analyst is processing a complex aggregation on a table with zero null values and the query returns the following result:
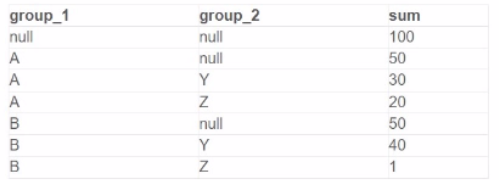
Which query did the analyst execute in order to get this result?
A)

B)
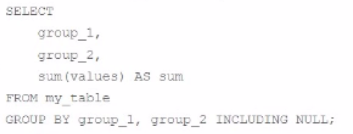
C)

D)

Answer : B